




Background
As you may know, I am the author and maintainer of the PHP League's CommonMark Markdown parser. This project has three primary goals:
- Fully support the entire CommonMark spec.
- Match the behavior of the JS reference implementation.
- Be well-written and super-extensible so that others can add their own functionality.
This last goal is perhaps the most challenging, especially from a performance perspective. Other popular Markdown parsers are built using single classes with massive regex functions. As you can see from this benchmark, it makes them lightning fast:
| Library | Avg. Parse Time | File/Class Count |
|---|---|---|
| Parsedown 1.6.0 | 2 ms | 1 |
| PHP Markdown 1.5.0 | 4 ms | 4 |
| PHP Markdown Extra 1.5.0 | 7 ms | 6 |
| CommonMark 0.12.0 | 46 ms | 117 |
Unfortunately, because of the tightly-coupled design and overall architecture, it's difficult (if not impossible) to extend these parsers with custom logic.
For the League's CommonMark parser, we chose to prioritize extensibility over performance. This led to a decoupled object-oriented design which users can easily and customize. This has enabled others to build their own integrations, extensions, and other custom projects.
The library's performance is still decent - the end user probably can't differentiate between 42ms and 2ms (you should be caching your rendered Markdown anyway). Nevertheless, we still wanted to optimize our parser as much as possible without compromising our primary goals. This blog post explains how we used Blackfire to do just that.
Profiling with Blackfire
Blackfire is a fantastic tool from the folks at SensioLabs. You simply attach it to any web or CLI request and get this awesome, easy-to-digest performance trace of your application's request. In this post, we'll be examining how Blackfire was used to identify and optimize two performance issues found in version 0.6.1 of the league/commonmark library.
Let's start by profiling the time it takes league/commonmark to parse the contents of the CommonMark spec document:
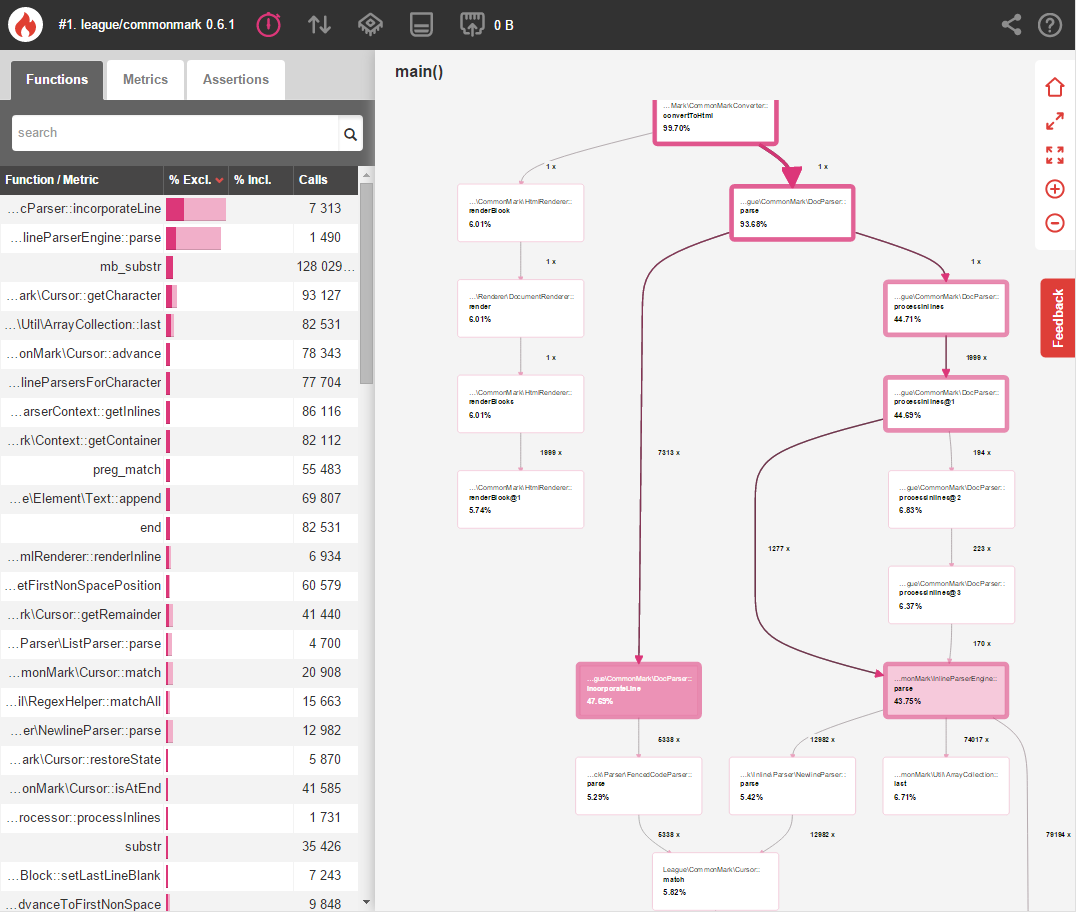
Later on we'll compare this benchmark to our changes in order to measure the performance improvements.
Quick side-note: Blackfire adds overhead while profiling things, so the execution times will always be much higher than usual. Focus on the relative percentage changes instead of the absolute "wall clock" times.
Optimization 1
Looking at our initial benchmark, you can easily see that inline parsing with InlineParserEngine::parse() accounts for a whopping 43.75% of the execution time. Clicking this method reveals more information about why this happens:
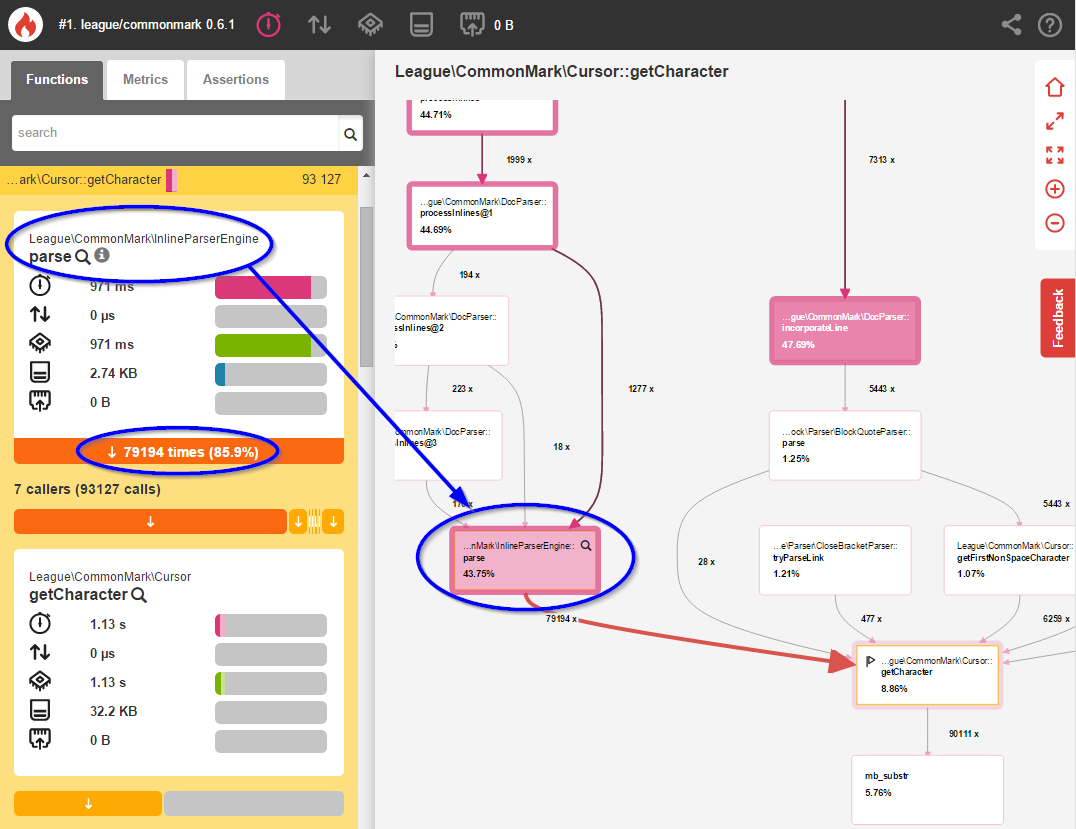
Here we see that InlineParserEngine::parse() is calling Cursor::getCharacter() 79,194 times - once for every single character in the Markdown text. Here's a partial (slightly-modified) excerpt of this method from 0.6.1:
public function parse(ContextInterface $context, Cursor $cursor)
{
// Iterate through every single character in the current line
while (($character = $cursor->getCharacter()) !== null) {
// Check to see whether this character is a special Markdown character
// If so, let it try to parse this part of the string
foreach ($matchingParsers as $parser) {
if ($res = $parser->parse($context, $inlineParserContext)) {
continue 2;
}
}
// If no parser could handle this character, then it must be a plain text character
// Add this character to the current line of text
$lastInline->append($character);
}
}
Blackfire tells us that parse() is spending over 17% of its time checking every. single. character. one. at. a. time. But most of these 79,194 characters are plain text which don't need special handling! Let's optimize this.
Instead of adding a single character at the end of our loop, let's use a regex to capture as many non-special characters as we can:
public function parse(ContextInterface $context, Cursor $cursor)
{
// Iterate through every single character in the current line
while (($character = $cursor->getCharacter()) !== null) {
// Check to see whether this character is a special Markdown character
// If so, let it try to parse this part of the string
foreach ($matchingParsers as $parser) {
if ($res = $parser->parse($context, $inlineParserContext)) {
continue 2;
}
}
// If no parser could handle this character, then it must be a plain text character
// NEW: Attempt to match multiple non-special characters at once.
// We use a dynamically-created regex which matches text from
// the current position until it hits a special character.
$text = $cursor->match($this->environment->getInlineParserCharacterRegex());
// Add the matching text to the current line of text
$lastInline->append($character);
}
}
Once this change was made, I re-profiled the library using Blackfire:
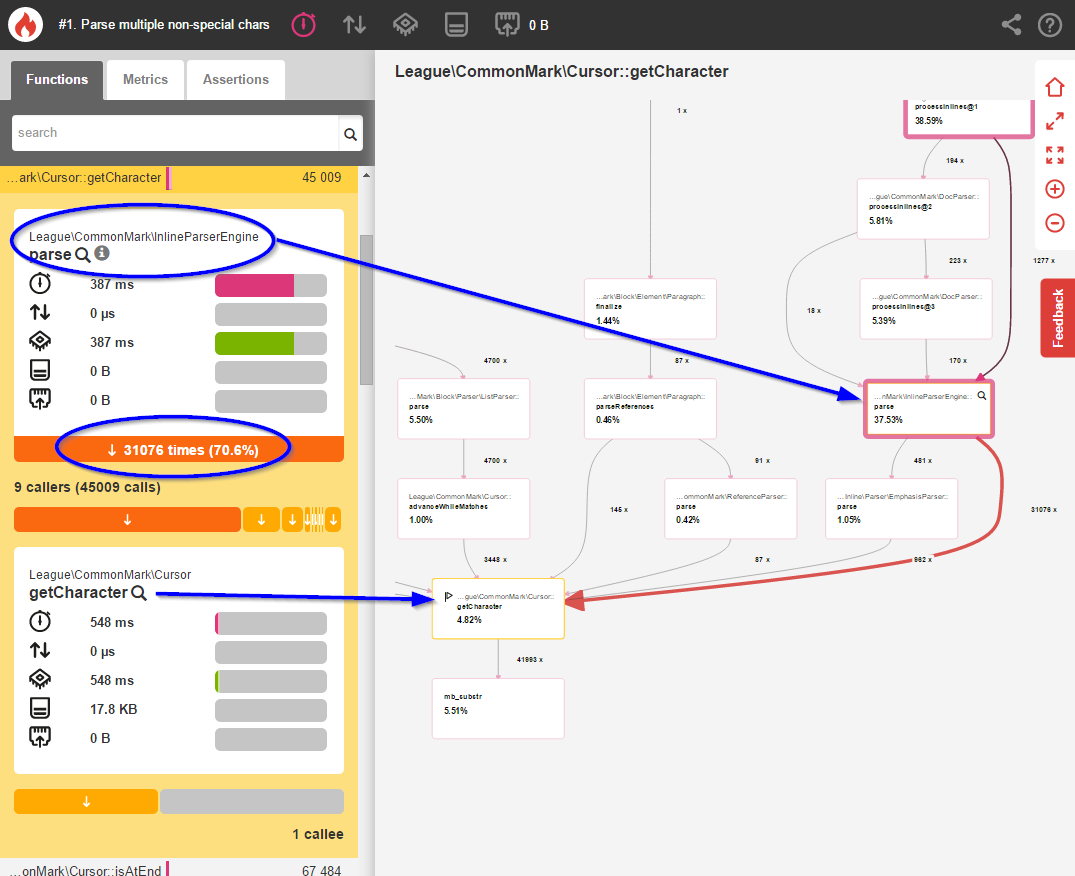
Okay, things are looking a little better. But let's actually compare the two benchmarks using Blackfire's comparison tool to get a clearer picture of what changed:
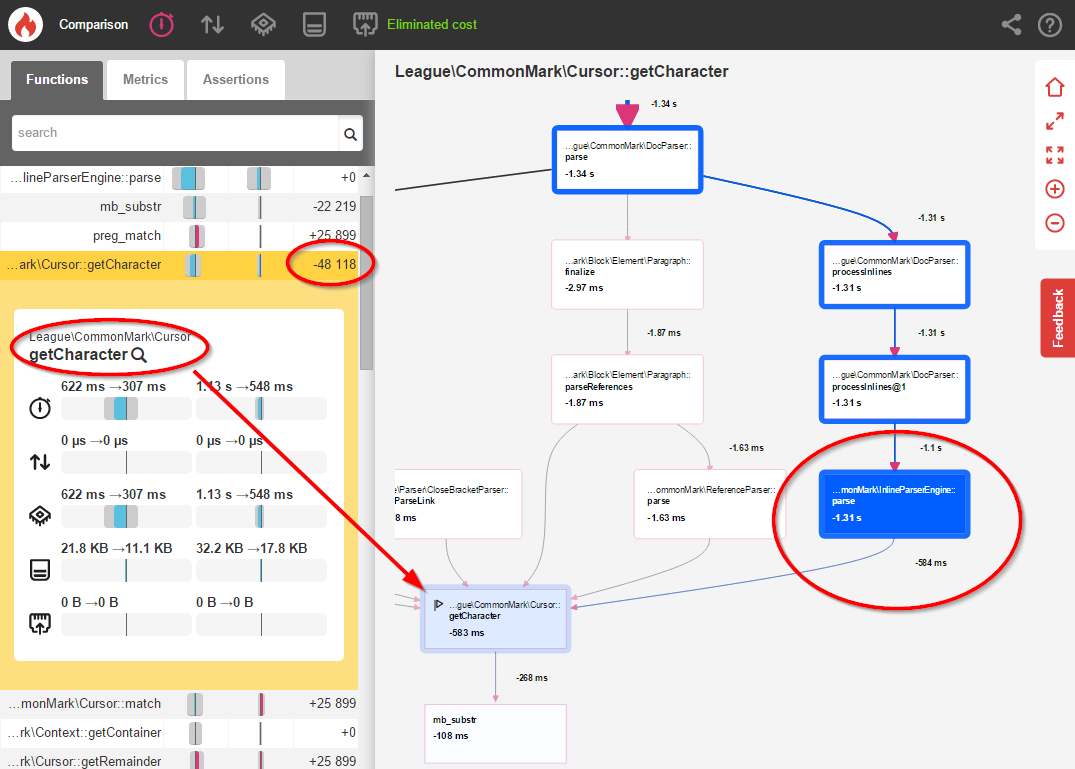
This single change resulted in 48,118 fewer calls to that Cursor::getCharacter() method and an 11% overall performance boost! This is certainly helpful, but we can optimize inline parsing even further.
Optimization 2
According to the CommonMark spec:
A line break ... that is preceded by two or more spaces ... is parsed as a hard line break (rendered in HTML as a <br /> tag)
Because of this language, I originally had the NewlineParser stop and investigate every space and \n character it encountered. Here's an example of what that original code looked like:
class NewlineParser extends AbstractInlineParser {
public function getCharacters() {
return array("\n", " ");
}
public function parse(ContextInterface $context, InlineParserContext $inlineContext) {
if ($m = $inlineContext->getCursor()->match('/^ *\n/')) {
if (strlen($m) > 2) {
$inlineContext->getInlines()->add(new Newline(Newline::HARDBREAK));
return true;
} elseif (strlen($m) > 0) {
$inlineContext->getInlines()->add(new Newline(Newline::SOFTBREAK));
return true;
}
}
return false;
}
}
Most of these spaces weren't special, and it was therefore wasteful to stop at each one and check them with a regex. You can easily see the performance impact in the original Blackfire profile:
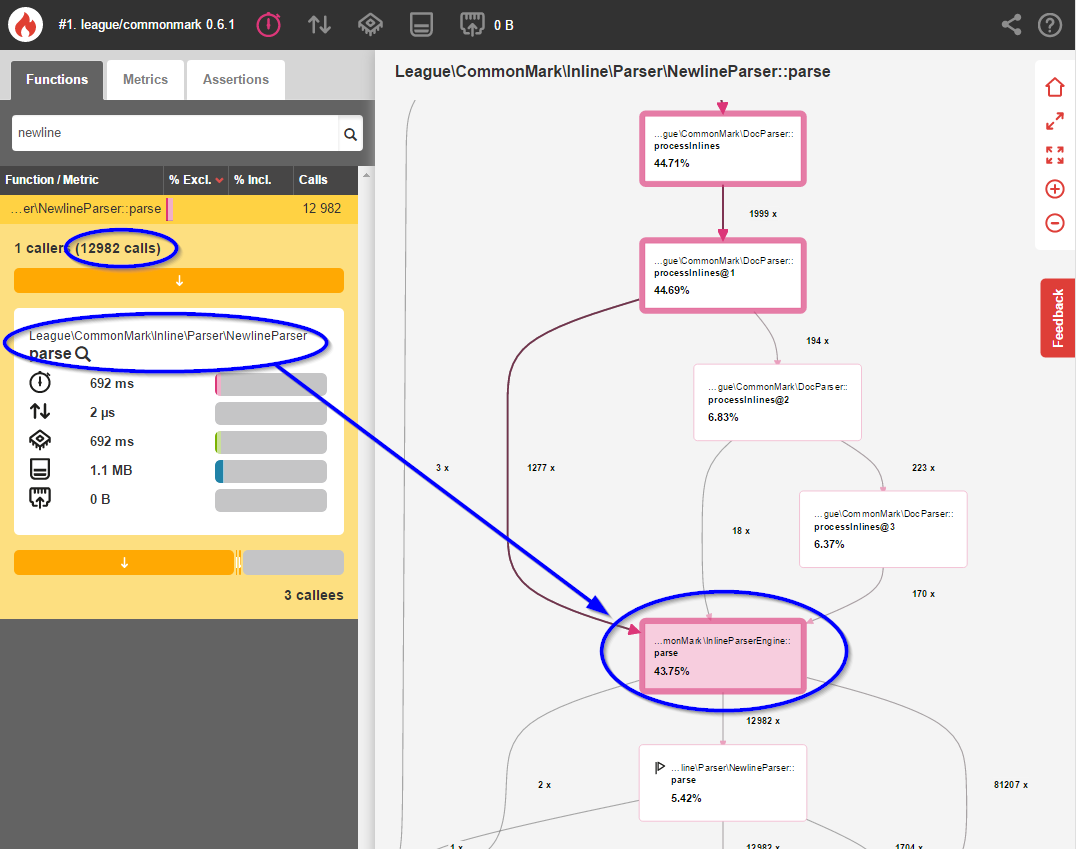
I was shocked to see that 43.75% of the ENTIRE parsing process was figuring out whether 12,982 spaces and newlines should be converted to <br> elements. This was totally unacceptable, so I set out to optimize this.
Remember that the spec dictates that the sequence must end with a newline character (\n). So, instead of stopping at every space character, let's just stop at newlines and see if the previous characters were spaces:
class NewlineParser extends AbstractInlineParser {
public function getCharacters() {
return array("\n");
}
public function parse(ContextInterface $context, InlineParserContext $inlineContext) {
$inlineContext->getCursor()->advance();
// Check previous text for trailing spaces
$spaces = 0;
$lastInline = $inlineContext->getInlines()->last();
if ($lastInline && $lastInline instanceof Text) {
// Count the number of spaces by using some `trim` logic
$trimmed = rtrim($lastInline->getContent(), ' ');
$spaces = strlen($lastInline->getContent()) - strlen($trimmed);
}
if ($spaces >= 2 ) {
$inlineContext->getInlines()->add(new Newline(Newline::HARDBREAK));
} else {
$inlineContext->getInlines()->add(new Newline(Newline::SOFTBREAK));
}
return true;
}
}
With that modification in place, I re-profiled the application and saw the following results:
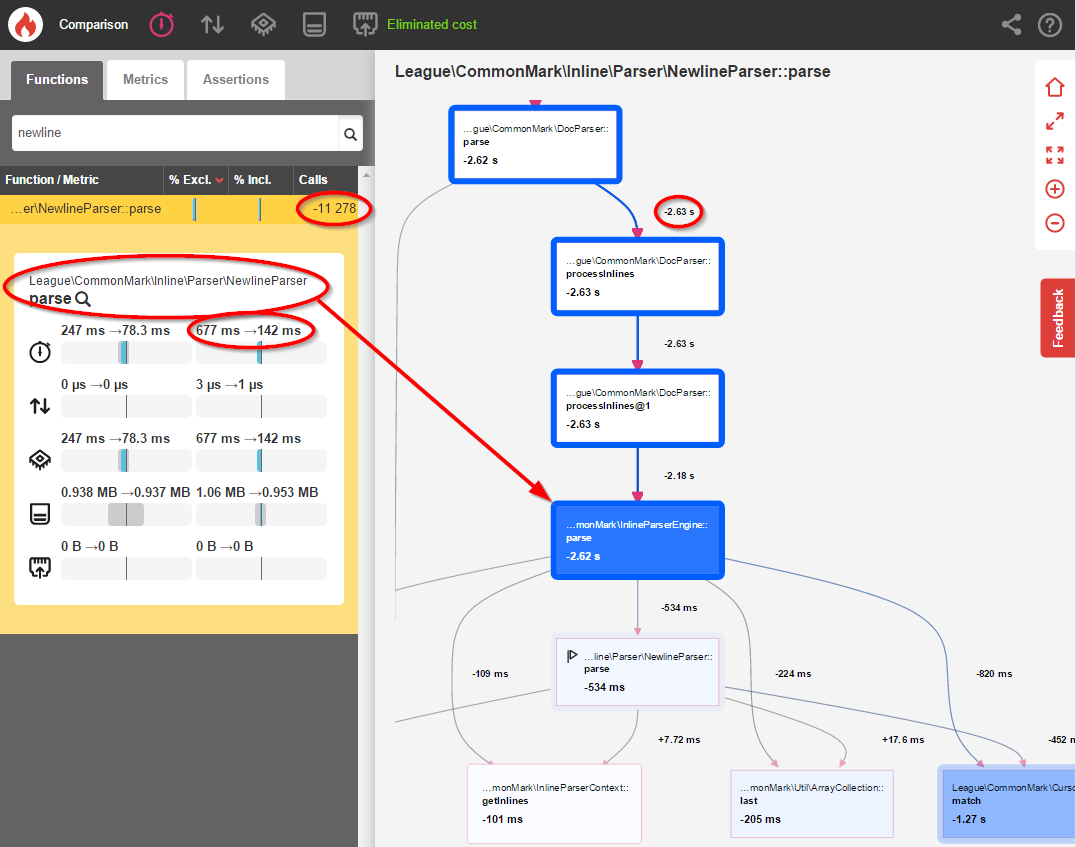
NewlineParser::parse()is now only called 1,704 times instead of 12,982 times (an 87% decrease)- General inline parsing time decreased by 61%
- Overall parsing speed improved by 23%
Summary
Once both optimizations were implemented, I re-ran the league/commonmark benchmark tool to determine the real-world performance implications:
- Before:
- 59ms
- After:
- 28ms
That's a whopping 52.5% performance boost from making two simple changes!
Being able to see the performance cost (in both execution time and number of function calls) was critical to identifying these performance hogs. I highly doubt these issues would've been noticed without having access to this performance data.
Profiling is absolutely critical to ensuring that your code runs fast and efficiently. If you don't already have a profiling tool then I highly recommend you check them out. My personal favorite happens to be Blackfire (which is "freemium"), but there other profiling tools out there too. All of them work slightly differently, so look around and find the one that works best for you and your team.
Full disclosure: Although this post will be submitted to Blackfire's #FireUpMyMac contest, I was not paid to write this post - I honestly enjoy using Blackfire and wanted to share my experiences with it.
Enjoy this article?
Support my open-source work via Github or follow me on Twitter for more blog posts and other interesting articles from around the web. I'd also love to hear your thoughts on this post - simply drop a comment below!
